虚树
什么是虚树
虚树常常被使用在树形dp中,就比如这题。当一次询问仅仅涉及到整颗树中少量结点时,为每次询问都对整棵树进行dp在时间上是不可接受的。此时,我们建立一颗仅仅包含部分关键结点的虚树,将非关键点构成的链简化成边或是剪去,在虚树上进行dp。
虚树包含所有的询问点及它们之间的LCA。显然虚树的叶子节点必然是询问点,因此对于某次含有k个点的询问,虚树最多有K个叶子结点,从而整颗虚树最多只有2k-1个结点(这会在虚树变成二叉树形态时达到)。
建立虚树之前
我们需要:
预处理出原树的dfs序以及dp可能用到的一些其他东西。
高效的在线LCA算法,单次询问O(logn)的倍增和树剖,O(1)的RMQ−ST皆可。
将询问点按dfs序排序。
如何建立虚树
最右链是虚树构建的一条分界线,表明其左侧部分的虚树已经完成构建。我们使用栈stak来维护所谓的最右链,top为栈顶位置。值得注意的是,最右链上的边并没有被加入虚树,这是因为在接下来的过程中随时会有某个lca插到最右链中。
初始无条件将第一个询问点加入栈stak中。
将接下来的所有询问点顺次加入,假设该询问点为now,lc为该点和栈顶点的最近公共祖先即lc=lca(stak[top],now)。
由于lc是stak[top]的祖先,lc必然在我们维护的最右链上。
考虑lc和stak[top]及栈中第二个元素stak[top-1]的关系。
情况一
lc = stak[top],也就是说,now在stak[top]的子树中
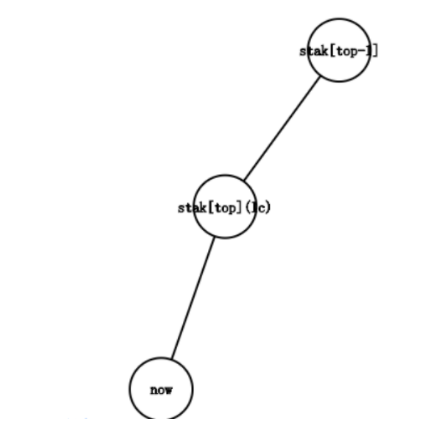
这时候,我们只需把now入栈,即把它加到最右链的末端即可。
情况二
lc在stak[top]和stak[top-1]之间。
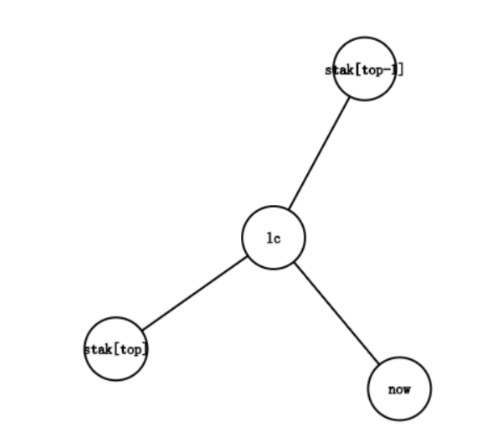
显然,此时最右链的末端从stak[top-1]->stak[top]变成了stak[top-1]->lc->stak[top],我们需要做的,首先是把边lc-stak[top]加入虚树,然后,把stak[top]出栈,把lc和now入栈。
情况三
lc=stak[top−1]。
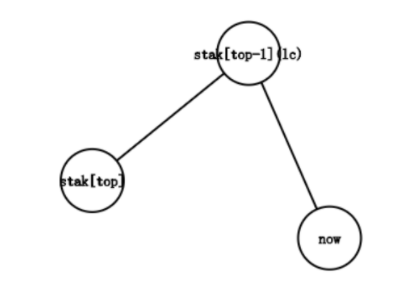
这种情况和第二种情况大同小异,唯一的区别就是lc不用入栈了。
情况四
此时有dep[lc]<dep[stak[top-1]]。lc已经不在stak[top-1]的子树中了,甚至也未必在stak[top-2],stak[top-3]……的子树中。
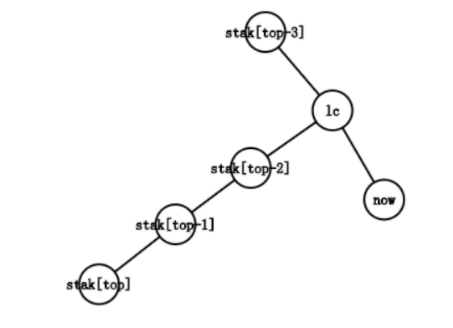
以图中为例,最右链从stak[top-3]->stak[top-2]->stak[top-1]->stak[top]变成了stak[top-3]->lc->now。我们需要循环依次将最右链的末端剪下,将被剪下的边加入虚树,直到不再是情况四。
就上图而言,循环会持续两轮,将stak[top],stak[top-1]依次出栈,并且把边stak[top-1]-stak[top],stak[top-2]-stak[top-1]加入虚树中。随后通过情况二完成构建。
当最后一个询问点加入之后,再将最右链加入虚树,即可完成构建。
另一种虚树构建方法:欧拉序
什么是欧拉序
正常的dfs序仅在入栈的时候计算一次,而欧拉序,不仅在入栈的时候计算一次,还在出栈的时候计算一次,也就是说一个点有两次出现机会压栈为+,弹栈为-,欧拉序记录了dfs的全部信息,只要有了这个树的欧拉序,就算没有树,给我们一个栈,照样可以在树上跑dfs。
我们发现,抽出来的那只树,它的欧拉序大小关系和原来的树的欧拉序是一样的,所以只需要把所有点的复制一个弹出点,然后把压栈点和弹栈点按原来树上的欧拉序排一波序,就是新树中的点按欧拉序排序的结果,然后欧拉序我们有了,直接不建树跑dfs即可